SandwichNet


Computers can crunch numbers in seconds that would take us humans hours to process. But for a long time, the opposite was also the case. In many simple classification problems, we humans were faster and more accurate than computers, for example, in the domains of image and sound classification. Today, we still outperform computers in some complex classification problems, in others we don’t stand a chance against modern machine learning algorithms. The back propagation algorithm is one of the main reasons this is possible. It gradually improves a randomly initiated model until it reaches the programmed goal.
Teaching neural nets and machine learning to students of non-technical disciplines often gets tricky when we look at what goes on within the training process of a model. While a parametric model with thousands to billions of parameters configured to output correct approximate predictions is already pretty complex, understanding the overarching principle that makes modern machine learning algorithms possible is key. And that’s where the back propagation algorithm comes in.
Inspired by a particularly simple and memorable example from the textbook: “You Look like a Thing and I Love You” from Janelle Shane (Wildfire, 2020), we created an interactive web application that lets students copy the actions of a training algorithm.
We’re using the tool in our foundational machine learning courses to help students understand the possibilities and limitations of the technology better down the road. We really believe that teaching these highly technical concepts in a hands-on way will benefit the students when they start working on technologically complex problems and projects in the future.
Classification algorithms are pretty amazing, but when you get down to it, the magic is just a bunch of familiar multiplications and additions, plus some pretty simple methods that introduce non-linear functionality. The history of neural nets, like the mathematically simple Perceptron, can help design students see that deep learning is totally within their grasp.
But what is needed to put our neurons to use is some training data and an algorithm, which is able to bend our neurons to our will.
We’re going to start talking about derivatives and slopes, which might get a bit technical. But we think it’s worth zooming in on this optimization process instead of treating it as a black box. To do this, we’ve implemented a very simple neural net:
SandwichNet
In a fictional universe, mysterious random sandwiches emerge from a magic portal. Our goal is to train an algorithm that can estimate whether a sandwich that just entered our dimension will be tasty or disgusting.
This is where our tool comes into the game: SandwichNet visualizes a simple neural network consisting of a few fully connected layers. The tool has three levels, which cover the different levels of complexity in the learning content.
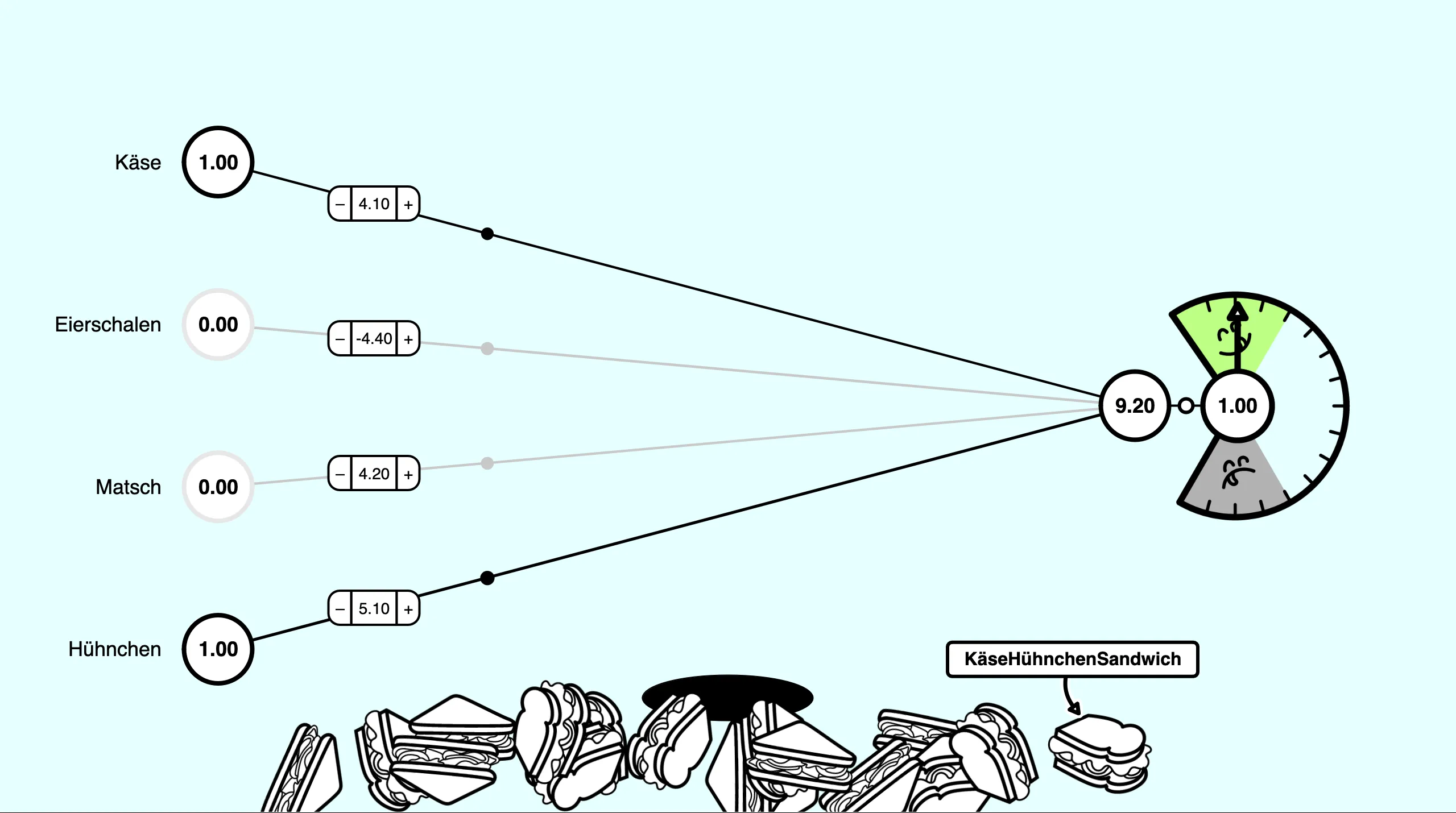 First level of SandwichNet, similar to perception
First level of SandwichNet, similar to perception
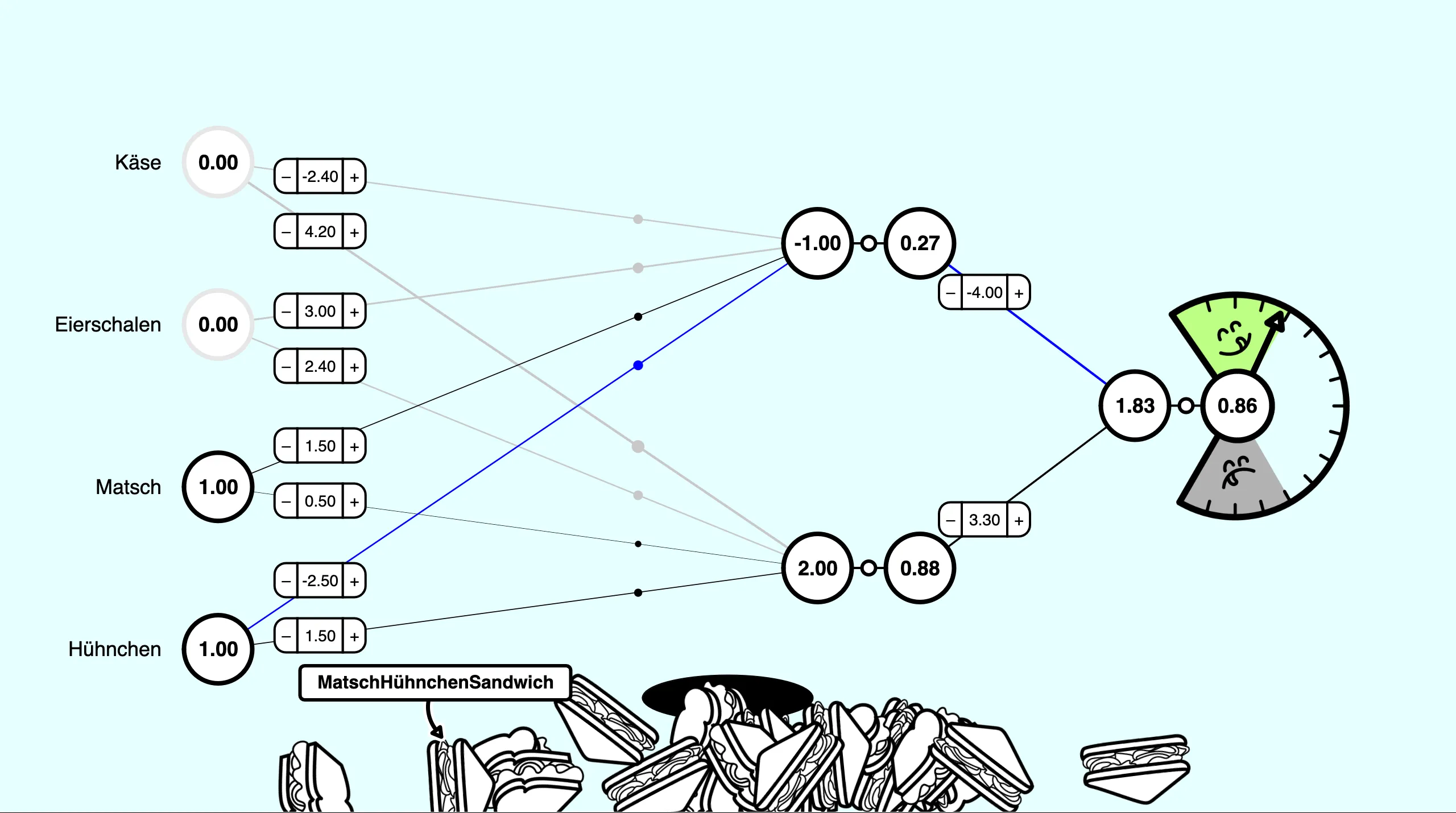 Second level of SandwichNet with a hidden layer
Second level of SandwichNet with a hidden layer
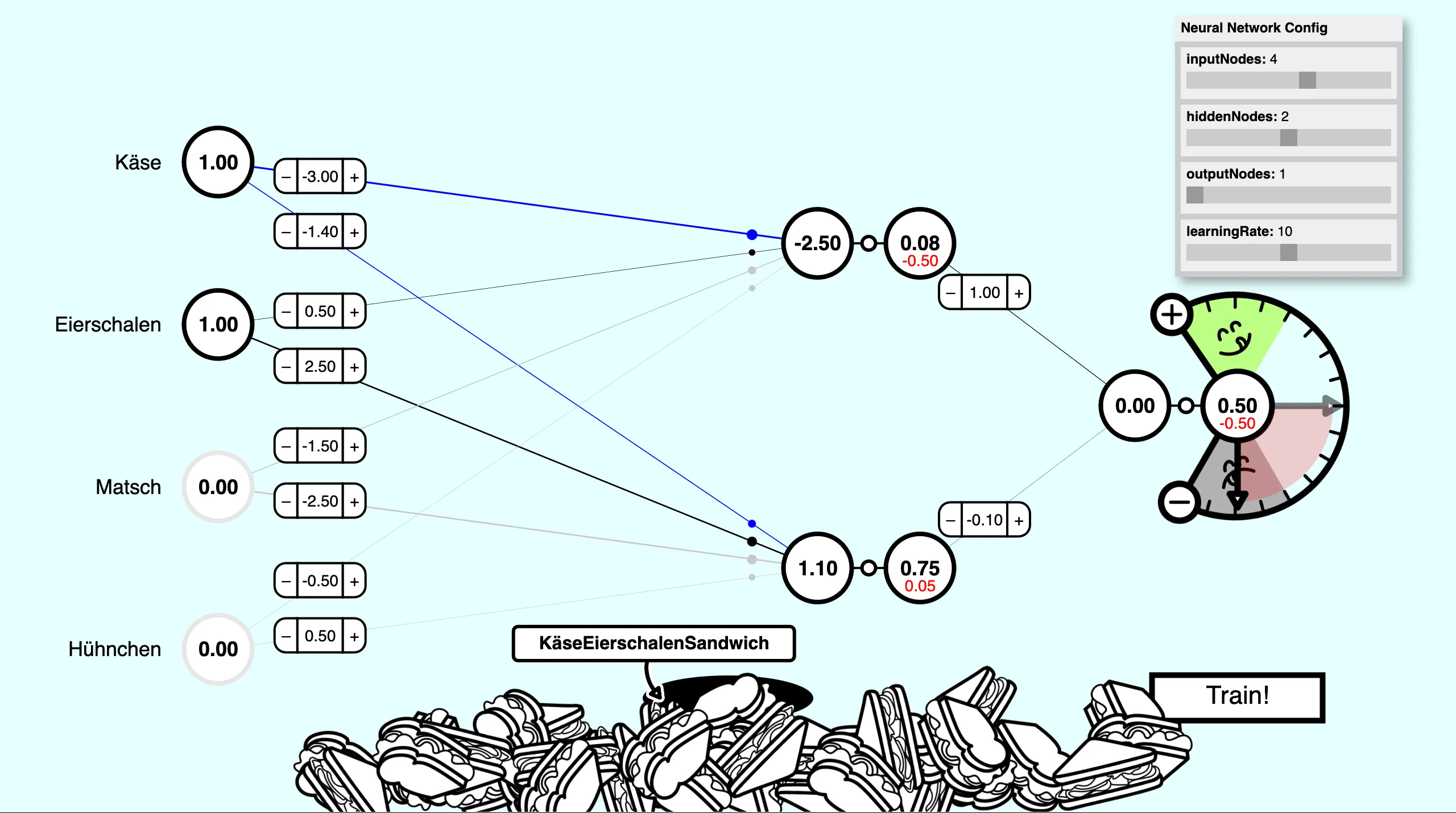 Third level of SandwichNet with the semi-automatic backpropagation process
Third level of SandwichNet with the semi-automatic backpropagation process
When you click on the “magic portal” (the black oval in the center of the bottom), data samples appear, represented by sandwiches with randomly selected ingredients. The ingredients are translated into numerical values for the input layer of SandwichNet. The output layer has one neuron that predicts how tasty each sandwich combo is. To show not only the bare number at the end, we get help from a “Taste-O-Meter”, a circular scale with a needle, to indicate how tasty a sandwich combination is. The needle moves up into the green area if the prediction is a delicious sandwich, or down into the grey area if it’s inedible.
So, in level one and two, we’re going to train our own neural network by tweaking the weights of each individual neuron by increasing or decreasing their values and immediately classify the randomly generated sandwiches.
In the third level of SandwichNet, we’ve moved away from manually adjusting the weights. Now, we’re optimizing SandwichNet in a semi-automated process using backpropagation. We can use the plus and minus buttons on the “Taste-O-Meter”-scale to specify the error by determining a value that should be the correct result of the prediction. This means calculating the output with randomly initialized weights and then calculating the difference between the resulting and expected values. Once we know how much the deviation is off, we adjust the weights by clicking the train button to get the error down. We can keep doing this until the neural network makes the right predictions.
Feel free to give it a try on the links below. You can use it in your own classes and adapt it to suit your needs. The code is provided via a GitHub repository.
Ressources
-
Shane, Janelle. You Look like a Thing and I Love You. Wildfire, 2020.
-
p5js (https://p5js.org/)
-
Links to the individual different levels of SandwichNet:
- Level 1 - The basic concept of the perceptron from the 1950s:
- Level 2 - An extended perceptron with a hidden layer, developed around the 1970s:
- Level 3 - Semi-automated learning process using the backpropagation algorithm:
- Level 4 - Automated learning process using the backpropagation algorithm:
-
GitHub repository of SandwichNet: